65
Plants
2.5GW
Capacity connected
12000+
Assets years of data
1300+
Assets
Are your assets producing the maximum power they can? Can you tell if one of the turbines is going to fail soon?
Are your assets properly taken care of? Availability metrics and full-service agreements rarely give the full story about what’s going on with your assets.
With Kavaken, you get specific action recommendations regarding the most critical questions about your your fingertips. Without installing any new hardware, ensure production is maximized, risks are reduced and your team is happy.
And you can do all this without;
- Additional investments
- Expanding resources
- Complex SCADA and Excel screens

“We have benefited from our cooperation while securing a tangible impact on the availability and power curves thanks to the cases granted by Kavaken. We also support further development of the platform which leads to additional value generation for our portfolio.”

“We’ve been using Kavaken’s Forecast+ module since early 2021 and have been pleased to see how they have consistently delivered the best forecast. As reducing balancing costs and generating more revenue becomes ever more important, we’re excited to take our collaboration with Kavaken further.”

“We are grateful to Kavaken for enabling us to verify the results of our upgrading efforts in the field through data-driven insights. Since embracing Kavaken’s platform, our team has been able to streamline many processes and complete the work much faster compared to traditional manual methods. This not only saved us a significant amount of time, but also allowed us our team to gain new capabilities without the need for expanding our workforce.”

“We have been working with multiple providers for more than 5 years. Thanks to Kavaken's solutions we have achieved the highest accuracy in our production forecasts in all of our plants.”

“With Kavaken’s Asset Management capabilities, we detected an undesirable condition very early on, avoiding a potential break-down of a major component.”











Predictive Maintenance
Minimize lost revenue
Receive advance warning to prevent failure of main components and revenue loss via harnessing vibration and SCADA data.
- Powered by vast set of AI algorithms and features
- Works with all turbine makes & models
- Enables deep dive analyses with heatmaps
Power Booster
Maximize output
Ensure your turbines are producing at their max at all times and analyze how the power curve is shifting through time.
- Uses IEC approved methods for filtering and analysis
- Identifies and alerts low performing turbines automatically
- Enables deep dive analyses with heatmaps


Forecast +
Improve sales
Reduce balancing cost and operational expenses by improving day ahead and intraday forecasts and automation.
- Ensembling AI algorithms achieve highest accuracy
- Novel approach leverages alternative data for forecasting
- Works in cooperation with forecasts from other providers
Tracker:
Increase asset health
Achieve peace-of-mind by knowing the turbines are operating within normal behavior limits and human errors are eliminated.
- Learns via AI the normal working behavior for each turbine
- Allows for customizing alert thresholds
- Alerts unwanted changes caused by human intervention
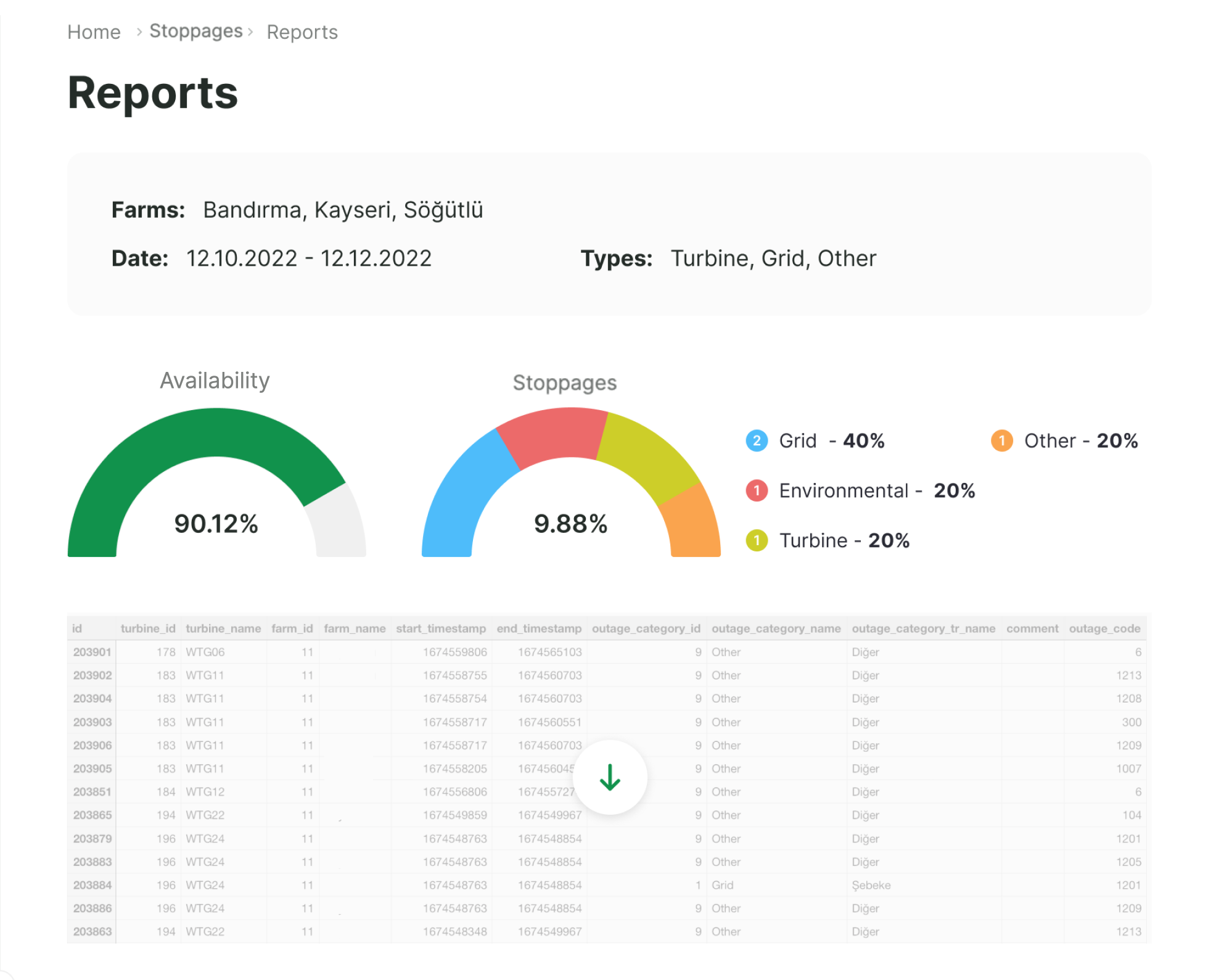
Outages
Automate outage tracking
Be better prepared for contractual availability discussions with automated categorization of outages.
- Improved understanding of downtime reasons
- Effort-free categorization & reporting of availability
- Smart merging and categorization of simultaneously occurring outage alarm codes


Revenue Cockpit
Focus on key metrics
Stay on top of your farms by focusing on critical, revenue-centric metrics only.
- Keeps track of how much revenue is "lost" day by day
- Shows all plants on one dashboard
- Designed for top and middle management
Power curve analysis for Turkiye's wind industry
Availability of large amounts of data makes it possible to extract additional value from your wind turbines by using advanced data analytics, such as artificial intelligence and machine learning for production forecasting, predictive maintenance, performance optimization...
Get the Report ->.png)



Sign up to receive the latest news
.png)